Chcesz porozmawiać z AI, która działa na karcie Radeon lub procesorze Ryzen w twoim komputerze? Trenowanie lokalnych modeli LLM jest dostępne na sprzęcie AMD i potrafi wykorzystać zarówno NPU w procesorach, jak i możliwości kart graficznych.
Chatboty AI działające w chmurze mają dwie poważne wady. Przede wszystkim, karmimy je danymi, które mogą być poufne lub wręcz tajne, a potem nie wiadomo, kto i kiedy je wykorzysta. No i oczywiście każda awaria takiej usługi, czy po prostu internetu, odcina nas od pracy.
Rozwiązaniem są modele językowe działające lokalnie i wykorzystujące do tego moc kart graficznych, czy też dedykowanych koprocesorów (NPU – Neural Processing Unit) do przyśpieszania obliczeń związanych ze sztuczną inteligencją. Dobrym przykładem takiego oprogramowania jest NVIDIA ChatRTX (dawniej NVIDIA Chat with RTX) wykorzystujący moc kart GeForce.
O ile NVIDIA zdążyła wypuścić już dedykowaną do tego typu zadań aplikację, to w przypadku sprzętu AMD trzeba się posiłkować takimi narzędziami jak LM Studio – czyli oprogramowaniem do eksperymentowania z lokalnymi Dużymi Modelami Językowymi (LLM). Jeśli chcemy wykorzystać do obliczeń karty AMD, musimy znaleźć modele, które wspierają rozwiązanie ROCm (upraszczając, jest to taki odpowiednik NVIDIA CUDA dla kart Radeon).
Embed post Jak uruchomić NVIDIA Chat With RTX na karcie GeForce? Twoja lokalna AI bez połączenia z chmurą
Lokalna AI na karcie graficznej AMD Radeon lub procesorze Ryzen z NPU
Na ten moment (ROCm w wersji 6.02) w wersji na Windows (10 i 11) w pełni wspiera karty graficzne:
AMD Radeon Pro W7900, AMD Radeon Pro W7800, AMD Radeon Pro W6800, AMD Radeon RX 7900 XTX, AMD Radeon RX 7900 XT, AMD Radeon RX 7600, AMD Radeon RX 6950 XT, AMD Radeon RX 6900 XT, AMD Radeon RX 6800 XT, AMD Radeon RX 6800.
Natomiast częściowo (bez wsparcia HIP SDK) modele:
AMD Radeon Pro W6600, AMD Radeon RX 6750, AMD Radeon RX 6700 XT, AMD Radeon RX 6700, AMD Radeon RX 6650 XT, AMD Radeon RX 6600 XT AMD Radeon RX 6600.
W przypadku Linuksa są to modele AMD Radeon PRO W7900, AMD Radeon PRO W7800, AMD Radeon RX 7900 XTX, AMD Radeon RX 7900 XT i AMD Radeon RX 7900 GRE. Jako, że jeszcze niedawno były to wyłącznie topowe modele Radeo Pro W7000 to widać, że rozwój oprogramowania idzie pełną parą (wsparcie dostał nawet Radeon RX 7600, ale jeszcze nie modele pośrednie). Dobrze, bo do funkcjonalności rozwiązań NVIDII wciąż jeszcze sporo brakuje.
Jeśli z kolei chcemy wykorzystać do obliczeń NPU wbudowane w procesory, to prawdopodobnie zadziała to na każdym modelu, który może się pochwalić taką funkcją (np. AMD Phoenix, czyli seria Ryzen 8000G) – musimy jedynie wybrać model językowy, który oferuje takie wsparcie.
Instalacja i konfiguracja LM Studio
Pierwszym krokiem jest oczywiście pobranie LM Studio i jego instalacja. Następnie musimy pobrać jeden (z wielu dostępnych) modeli LLM. Jeśli chodzi o sprzęt, do akceleracji AI wykorzystałem Radeona Pro W7900 (48 GB VRAM).
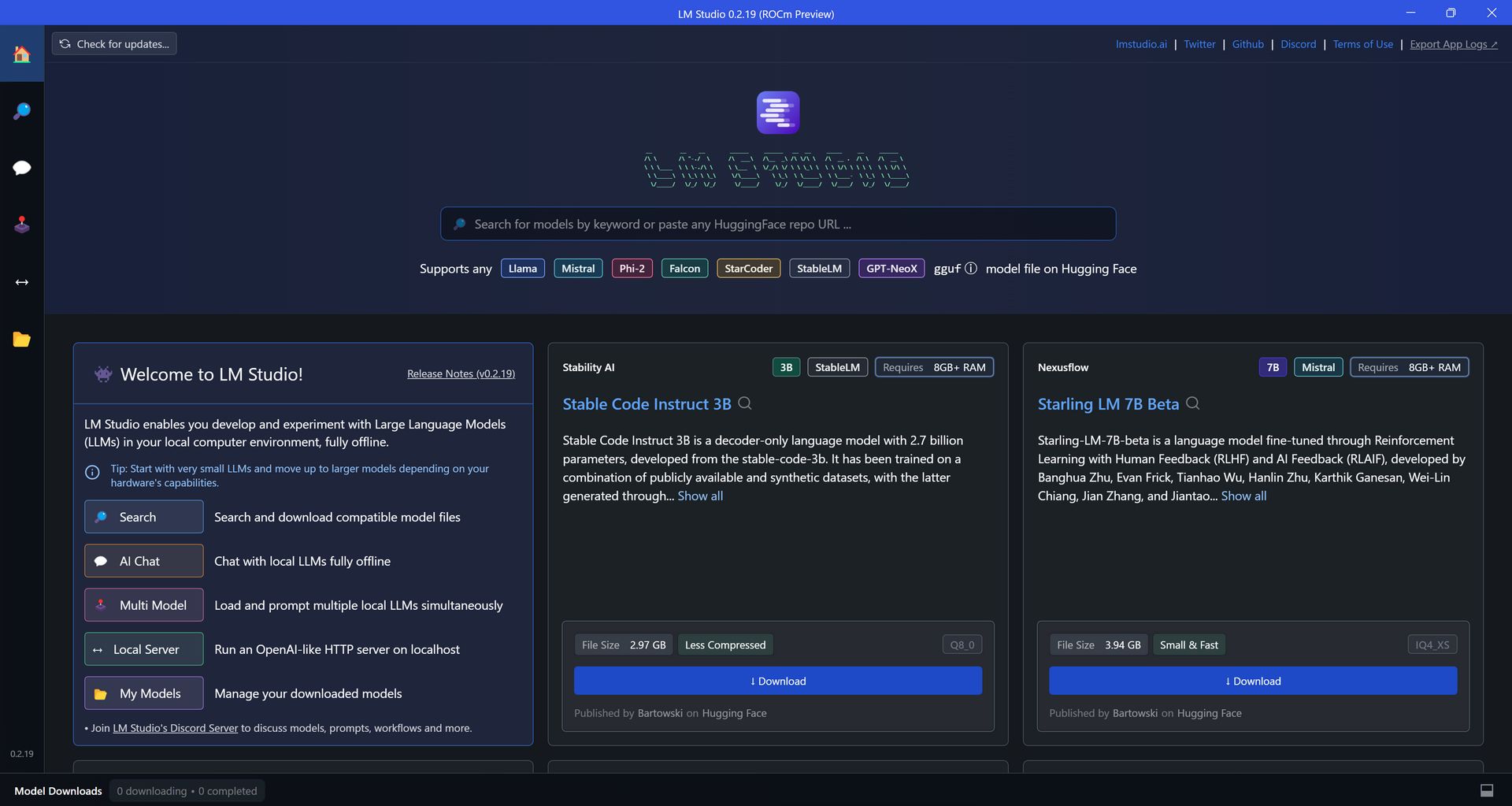
Na potrzeby tego poradnika wykorzystamy model Mistral. Wskazujemy konkretną wersję Mistrala, ale niech was to nie powstrzyma przed eksperymentowaniem – nie tylko z nowszymi wersjami, ale i z innymi modelami.
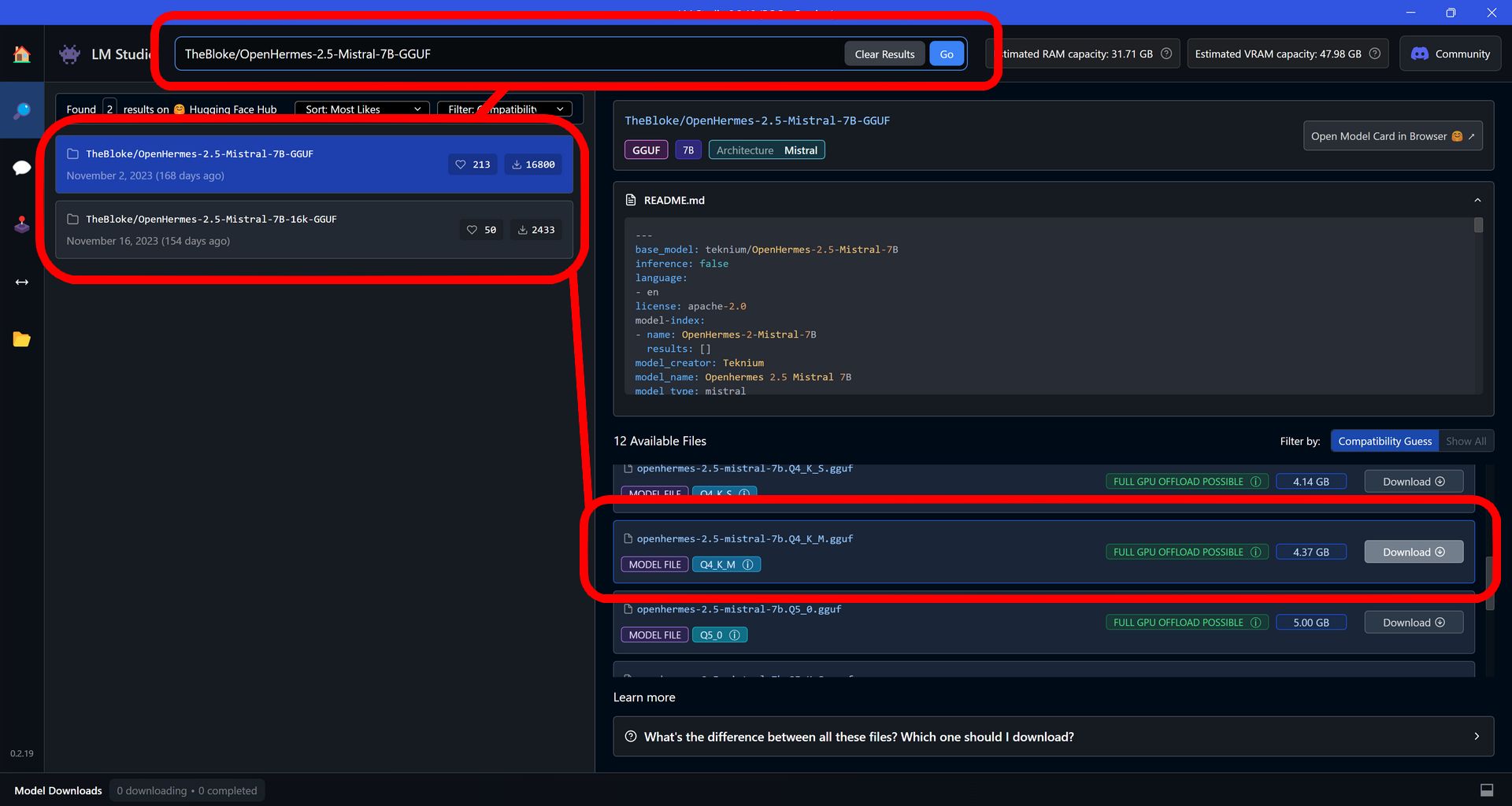
Wpisz w wyszukiwarce nazwę TheBloke/OpenHermes-2.5-Mistral-7B-GGUF i wybierz model. Po prawej stronie wybierz wersję Q4 K M, która powinna działać z większością procesorów Ryzen z NPU oraz oczywiście z obsługiwanymi kartami graficznymi.

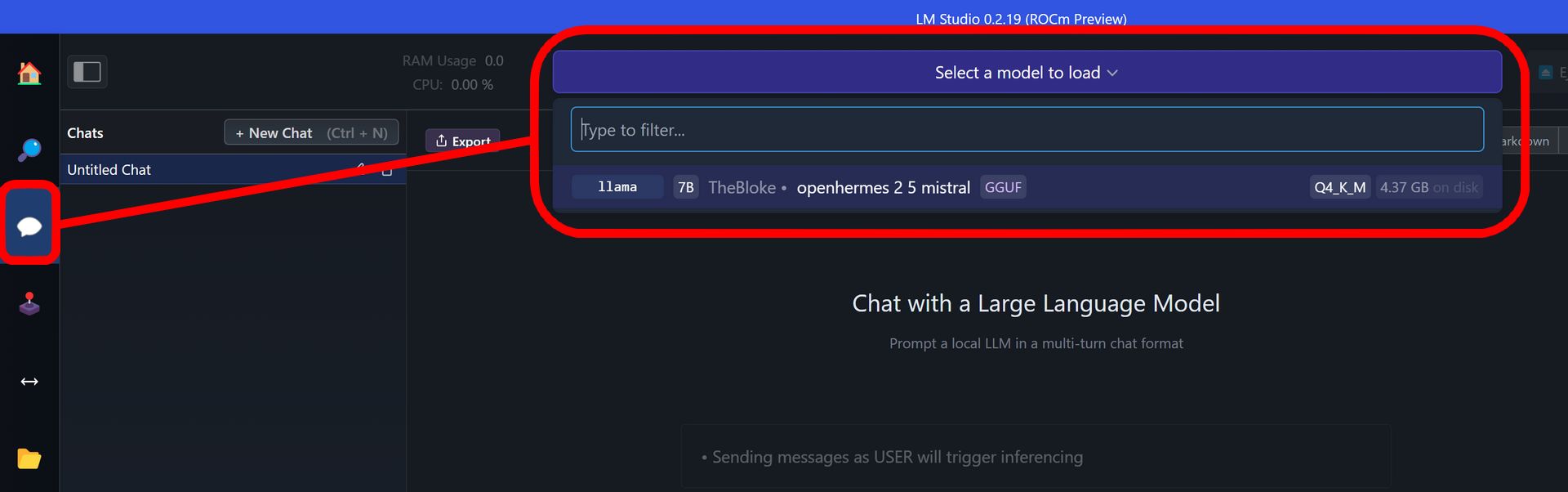
Wybrany model należy następnie pobrać (co może chwilę potrwać) i wybrać go do załadowania, co dokonuje się w menu Chat.
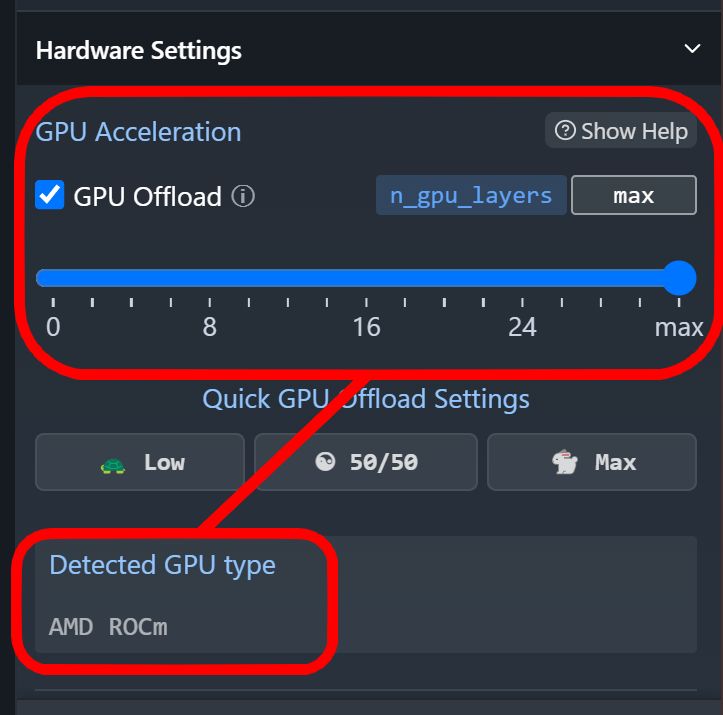
Jeśli chcesz uruchomić model na karcie graficznej Radeon, to przed jego trenowaniem upewnij się, że konfiguracja w pełni wykorzysta możliwości sprzętu. Wskaźnik GPU Offload powinien być ustawiony na maksimum, a wykryta karta graficzna (Detected GPU type) powinna korzystać z AMD ROCm.
Jeśli po zmianie konfiguracji wyskoczy ci błąd, po prostu przeładuj model na nowo. Wszystko gotowe, teraz możesz konwersować z AI i lokalnie go trenować, bez wysyłania danych do internetu.
Zobacz inne artykuły o sztucznej inteligencji:
Jaka karta graficzna do AI? Ranking najlepszych grafik do sztucznej inteligencji Sieci neuronowe – czym są i jak działają? Nie musisz być inżynierem, żeby znać podstawy Procesory Ryzen 8000G z mocarną zintegrowaną grafiką. Czekałem na te cudeńka prawie 3 lata
Twój lokalny bot AI na sprzęcie firmy NVIDIA (GeForce)
Jeśli do lokalnego trenowania LLM chcesz wykorzystać swoją kartę GeForce, to przypominamy, że służy do tego oprogramowanie NVIDIA Chat RTX. Wciąż jest w wersji demo, ale jest jak najbardziej funkcjonalne.
News Related-
Małgorzata Kożuchowska i Redbad Klynstra byli parą. Wygadała się Katarzyna Nosowska
-
Oto ile pieniędzy zarabiają nauczyciele w roku 2023/2024. Takie są ich wypłaty i dodatki. Zobacz minimalne wynagrodzenie 28.11.2023
-
Janek poszedł tylko po jedzenie dla królików. Został ciężko ranny
-
CCC przecenia skórzane kozaki Lasocki. Zachwycają prostym krojem. Okazje też w eobuwie, Deichmann
-
Nie minęło 48 godzin. Błaszczak musi się tłumaczyć z deklaracji
-
Dania ze szkolnej stołówki. Koszmar czy miłe wspomnienie z dzieciństwa? Tak gotowano w PRL
-
Rosja szykuje uderzenie? Putin zatwierdził plan ws. armii
-
Ekstraklasa siatkarek. Pewna wygrana ŁKS Commercecon Łódź
-
Dane medyczne Polaków w sieci. Niewiele można z tym zrobić (aktualizacja)
-
Burza stulecia paraliżuje południową Rosję i Krym; zalane autostrady i budynki, setki tysięcy ludzi bez prądu
-
Android Auto: odświeżone Mapy Google w kolejnych samochodach
-
Lech Wałęsa ujawnił, co zrobił z pieniędzmi za Pokojową Nagrodę Nobla. Piękny gest
-
"Milionerzy" - Tomasz szedł jak burza, ale poległ na pytaniu o byka
-
Urządzili kobietom piekło i uciekli. Usłyszeli zarzuty. Znamy szczegóły