Perplexity AI: Die Antwortmaschine bleibt Antworten schuldig
Der Chatbot des KI-Start-ups Perplexity AI soll mit Google konkurrieren können. Nun steht er in der Kritik, sich etwas zu aggressiv Informationen zu beschaffen.
Keine Such-, sondern eine Antwortmaschine: So inszeniert sich das KI-Start-up Perplexity AI in der Öffentlichkeit. Das US-Unternehmen entwickelt einen Chatbot, der auf das Internet zugreifen und Antworten auf Fragen mithilfe von künstlicher Intelligenz zusammenfassen können soll – mit Verweis auf die jeweiligen Quellen.
Perplexity will sich von traditionellen Suchmaschinen wie Google abgrenzen, indem es keine Liste mit Links, sondern von einem KI-Sprachmodell erstellte Zusammenfassungen erzeugt. Die Idee: Anstatt sich mühsam durch verschiedene Websites klicken zu müssen, liefert Perplexity die gesuchten Infos gebündelt und aufbereitet direkt im Chatfenster. In einer Entdecken-Sparte finden sich automatisch aufbereitete aktuelle Nachrichtenthemen.
Seit der Gründung im August 2022 konnte Perplexity namhafte Unterstützer gewinnen. Nvidia-CEO Jensen Huang nutzt die Suche eigenen Angaben zufolge fast täglich, für Shopify-Gründer Tobias Lütke soll Perplexity zwischenzeitlich sogar Google ersetzt haben. Mindestens 250 Millionen US-Dollar will das Unternehmen in seiner aktuellen Finanzierungsrunde einsammeln, die Bewertung von Perplexity soll bei drei Milliarden US-Dollar liegen. Zu den Geldgebern gehören Amazon-Gründer Jeff Bezos und die frühere YouTube-Chefin Susan Wojcicki.
Doch in diesen Tagen wird Kritik an Perplexity laut. Es geht um die Frage, wie das Unternehmen an die Inhalte von Websites kommt – und ob es dabei möglicherweise Türen öffnet, die eigentlich verschlossen bleiben sollten.
Angestoßen hat die Debatte Anfang Juni die Nachrichtenseite Forbes. Dessen Journalisten hatten herausgefunden, dass Perplexity auf seiner Entdecken-Seite einen Beitrag veröffentlicht hatte, der Informationen aus mehreren Forbes-Artikeln enthielt, die hinter einer Bezahlschranke stehen. Teils wurde der Wortlaut eins zu eins übernommen, ebenso wie eine von Forbes angefertigte Illustration. Weitere Untersuchungen fanden heraus, dass auch exklusive Inhalte von CNBC und Bloomberg von Perplexity aufgegriffen wurden. Die Verweise auf die Originale waren dabei nicht immer offensichtlich. Das wirft die Frage auf: Plagiiert Perplexity schamlos Medieninhalte?
Perplexity AI soll robots.txt ignoriert haben
Am 15. Juni zeigte der Webentwickler Robb Knight in einem Blogbeitrag, dass Perplexity offenbar die robots.txt von Websites ignoriert. Dabei handelt es sich um eine Textdatei, die Betreiberinnen von Websites hochladen können, um darin gezielt die sogenannten Crawler beziehungsweise Bots von Suchmaschinen zu blockieren, die ständig und automatisch das Internet nach neuen Informationen durchsuchen. Man kann sich die robots.txt wie ein Hausverbotsschild an der Kneipe vorstellen, das besagt: Du darfst hier nicht rein. Was aber nicht heißt, dass es manche nicht trotzdem versuchen, wenn der Wirt gerade nicht hinguckt.
Die robots.txt diente viele Jahre dazu, Suchmaschinen wie Google, Bing oder das Internet Archive von der eigenen Website fernzuhalten, weil man nicht wollte, dass die Inhalte dort verlinkt oder gespeichert wurden. Durch künstliche Intelligenz erfährt die Textdatei nun neue Aufmerksamkeit. Längst sind es nämlich auch die Crawler von Unternehmen wie OpenAI, die durch das Netz krabbeln, um Daten zu sammeln, mit denen sich neue KI-Modelle trainieren lassen.
Vergangenes Jahr hat sich OpenAI dazu bekannt, die robots.txt zu beachten. Auch Perplexity will das eigentlich tun, doch offenbar nimmt man es in der Praxis damit nicht so ernst. Um das zu testen, hat Robb Knight einen Blogbeitrag aufgesetzt, der gezielt die Crawler von Perplexity ausschließen soll. Als er den Chatbot anschließend fragte, was hinter dem verlinkten Artikel steht, bekam er eine Zusammenfassung des Inhaltes. Jenem Inhalt, der Perplexity eigentlich nicht zur Verfügung stehen sollte. Das Technikmagazin Wired bestätigte Knights Experiment wenig später mit eigenen Versuchen.
Perplexity ignoriere die robots.txt nicht, sagte Firmengründer Aravind Srinivas vergangene Woche gegenüber Fast Company, es sei komplizierter: "Wir verlassen uns nicht nur auf unsere eigenen Webcrawler, sondern auch auf Crawler von Drittanbietern." Und es sei einer dieser externen Crawler gewesen, der die Vorgaben ignoriert habe. Um welchen Anbieter es sich handelt, dürfe er aus Gründen der Verschwiegenheit nicht sagen. Auch nicht, ob die Zusammenarbeit inzwischen beendet wurde. Gleichzeitig verwies Srinivas darauf, dass es sich bei der robots.txt um "keinen rechtlichen Rahmen" handele. Was insofern stimmt, als dass es sich dabei lediglich um eine Vereinbarung handelt, die man beachten oder ignorieren kann.
Im April erwähnte er in einem Forbes-Interview außerdem, dass jeder das freie Web durchsuchen könne. Das Vorgehen von Perplexity unterscheide sich nicht von der Art und Weise, wie Journalisten die Arbeit anderer Publikationen zitieren. An anderer Stelle sagte Srinivas, dass man "Fakten und Genauigkeit" schätze. Dabei scheint er vergessen zu haben, dass er es selbst in der Vergangenheit nicht so genau mit der Wahrheit nahm. In einem Podcast erzählte er unlängst unverblümt, wie er und seine Kollegen sich Zugriff auf Daten von Twitter verschafft hatten, indem sie gefälschte Accounts erstellten und frei erfundene wissenschaftliche Studien als Vorwand nahmen.
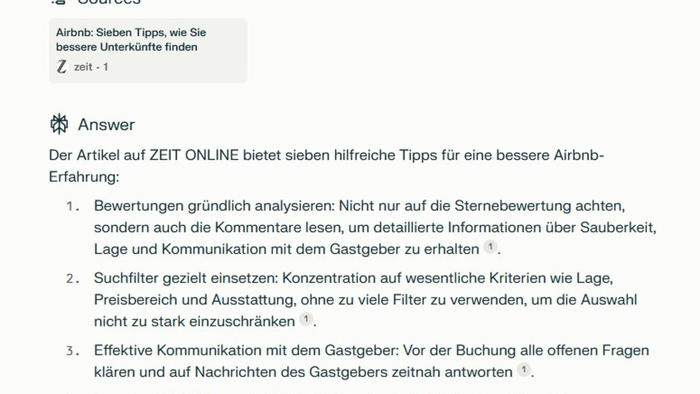
Unklar ist, wie es Perplexity gelungen ist, Inhalte wiederzugeben, die bei den Publishern hinter einer Paywall liegen – und ob Perplexity dies womöglich im großen Stil macht. Ein kurzer Test mit Bezahlinhalten von ZEIT ONLINE liefert darauf keine eindeutige Antwort. Auf die Frage, ob Perplexity den Z+-Artikel über sieben Tipps für bessere Airbnb-Buchungen zusammenfassen könne, antwortet der Bot zwar mit sieben Tipps, die aber nicht ganz mit denen im Artikel übereinstimmen, sondern teilweise auch von anderen Quellen stammen könnten. Der Tipp "Eine Packliste erstellen und sich über lokale Gepflogenheiten und Regelungen informieren" etwa kommt im Original gar nicht vor.
Allerdings erwähnt Perplexity, dass einer Studie zufolge 91 Prozent der Unterkünfte mindestens 4,5 Sterne haben – eine Information, die genau so im Text vorkommt. Und auch die Passage über mögliche Extras wie "Fahrradverleih oder Küchenausstattung", zwei recht spezielle Aspekte, die im Original stehen, lassen vermuten, dass der Bot womöglich doch hinter die Paywall gucken kann.
In einem zweiten Versuch haben wir Perplexity zunächst gefragt, wie DIE ZEIT über Nvidia berichtet. Hier verweist der Bot unter anderem auf einen aktuellen Bezahltext aus dieser Woche und erwähnt ein Zitat von Nvidia-CEO Jensen Huang, das auch im Text hinter der Schranke vorkommt. Allerdings griffen dieses Zitat auch zahlreiche andere Medien auf. Auf die Nachfrage, was Perplexity über den Inhalt des konkreten Z+-Artikels sagen kann, spricht der Bot dann nur von einem "Ausschnitt aus dem ZEIT-Artikel" und erwähnt keine Infos, die über die ersten Absätze hinausgehen.
Screenshot einer Anfrage an Perplexity AI
Die Erfahrungen decken sich mit denen des US-Magazins Wired. In manchen Fällen scheine es so, "als fasse Perplexity keine tatsächlichen Nachrichtenartikel zusammen, sondern nur deren Inhalt auf Grundlage von URLs und in Suchmaschinen hinterlassenen Spuren davon, wie etwa Auszügen und Metadaten", heißt es dort. Soll heißen: Wie andere KI-Chatbots baut auch Perplexity seine Antworten aus unterschiedlichen Quellen zusammen. Das würde erklären, weshalb Antworten und Verweise teils nicht immer übereinstimmen. Auch sind manche Antworten, wie bei anderen KI-Chatbots, schlicht erfunden, sprich halluziniert. Wired titelte: "Perplexity ist eine Bullshit-Maschine."
Große Herausforderungen für Publisher und Seitenbetreiber
Trotzdem ist es denkbar, dass sich Perplexity eine Art offizielle Hintertür zunutze macht, um an Paywall-Inhalte zu kommen. Diese gibt es, um beispielsweise Google den Zugriff auf den Volltext eines kostenpflichtigen Textes zu gewähren. Denn natürlich sollen auch Bezahlartikel in der Google-Suche auftauchen. Um sie indexieren zu können, muss Google wissen, was drinsteht. Die Crawler von Perplexity und dessen Partnern könnten diese, bildlich gesprochen, angelehnte Tür ausnutzen. Zumal viele Publikationen neue Dienste wie Perplexity AI vermutlich noch gar nicht auf dem Schirm haben und ihre Inhalte dementsprechend nicht vor ungewünschten Zugriffen schützen.
Am Ende zeigt die Debatte um Perplexity zwei Dinge: erstens die Herausforderungen, die auf alle Betreiber von Websites zukommen. Um den Datenhunger der KI-Firmen zu stoppen, sind jahrzehntealte Mittel wie die Verwendung einer robots.txt womöglich nicht geeignet. Es braucht neue, verpflichtende und standardisierte Verfahren, mit denen es möglich ist, die Verwendung von Text, Bildern, Video und Audio für künstliche Intelligenz einzuschränken.
Zweitens zeigt der Trend zu sogenannten Zero-Click-Searches, also zu Suchen im Internet, an deren Ende kein Klick mehr auf die ursprüngliche Website stattfinden muss, welche Herausforderungen auf Publisher und Medienorganisationen zukommen. Die Debatte um das Leistungsschutzrecht, in der es darum geht, welchen Inhalt und wie viel davon Suchmaschinenbetreiber ohne finanzielle Gegenleistung wiedergeben dürfen, könnte durch Antwortmaschinenbetreiber wie Perplexity AI schon bald eine Renaissance erfahren. Ausgang ungewiss.